Spark Performance Optimization Series: #1. Skew
$ 21.99 · 4.9 (660) · In stock

In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…
Handling Data Skew in Apache Spark: Techniques, Tips and Tricks to Improve Performance, by Suffyan Asad

Spark Performance Tuning & Best Practices - Spark By {Examples}

List: DataEng, Curated by Bruno Servilha
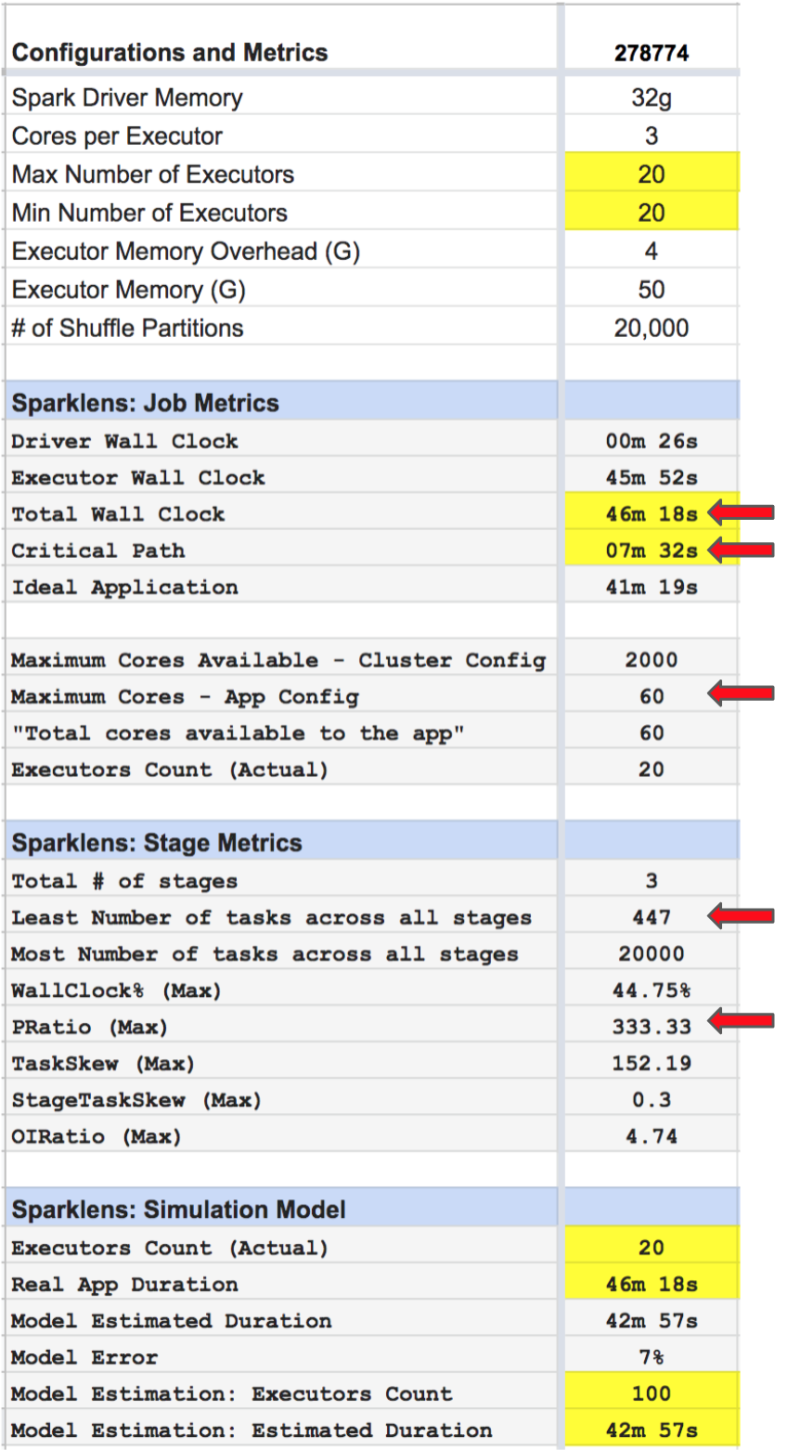
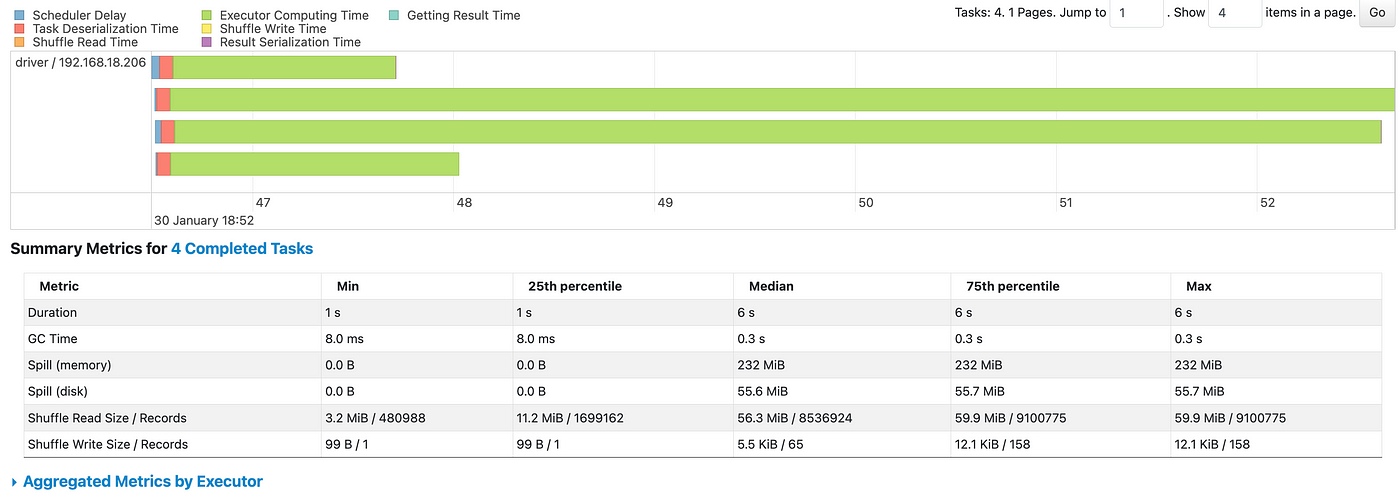
Spark Application Optimization for Performance using Qubole Sparklens

Apache Spark Core—Deep Dive—Proper Optimization

Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering

Stream Data from Kinesis to Databricks with Pyspark, by Himansu Sekhar, road to data engineering

Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai
Databricks Notebook Promotion using Azure DevOps, by Himansu Sekhar, road to data engineering
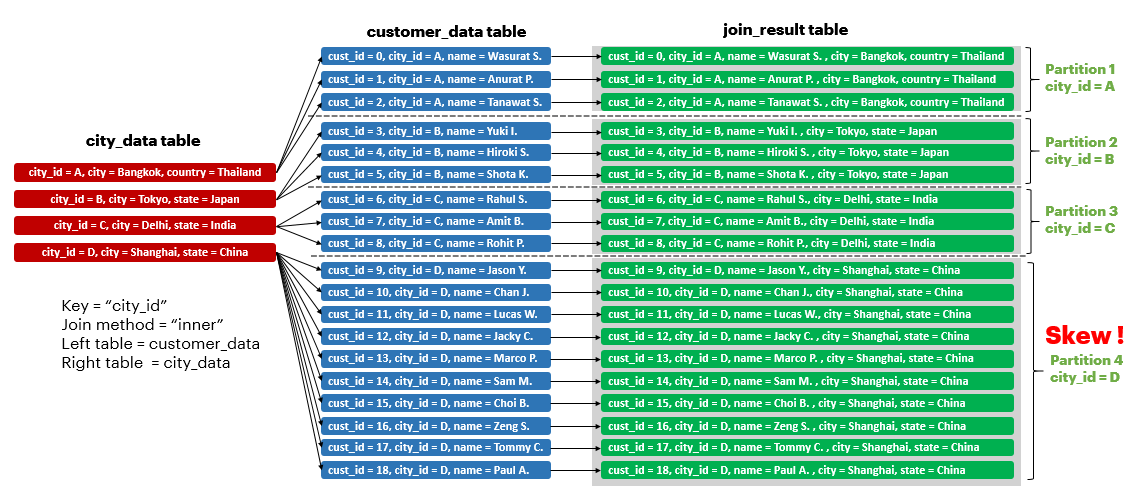
Spark Performance Tuning: Skewness Part 2, by Wasurat Soontronchai

The 5S Spark Optimization Series, Part 2: Tackling Skew Optimization for Balanced Excellence!, by Chenglong Wu

Data-induced predicates for sideways information passing in query optimizers

List: Reading list, Curated by mohit chaurasia