We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on
$ 17.50 · 4.9 (726) · In stock
Finetuning CLIP (Contrastive Language-Image Pre-training), by Abdulkader Helwan

Ananya Kumar's research works Stanford University, CA (SU) and other places
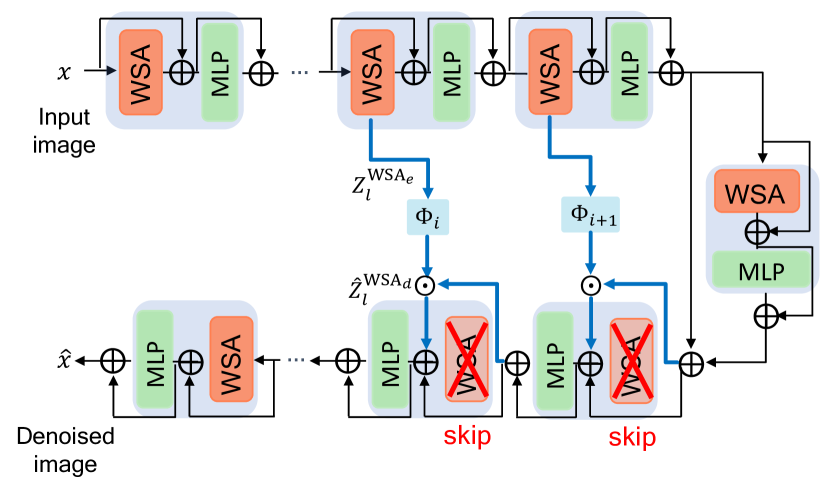
2301.02240] Skip-Attention: Improving Vision Transformers by Paying Less Attention
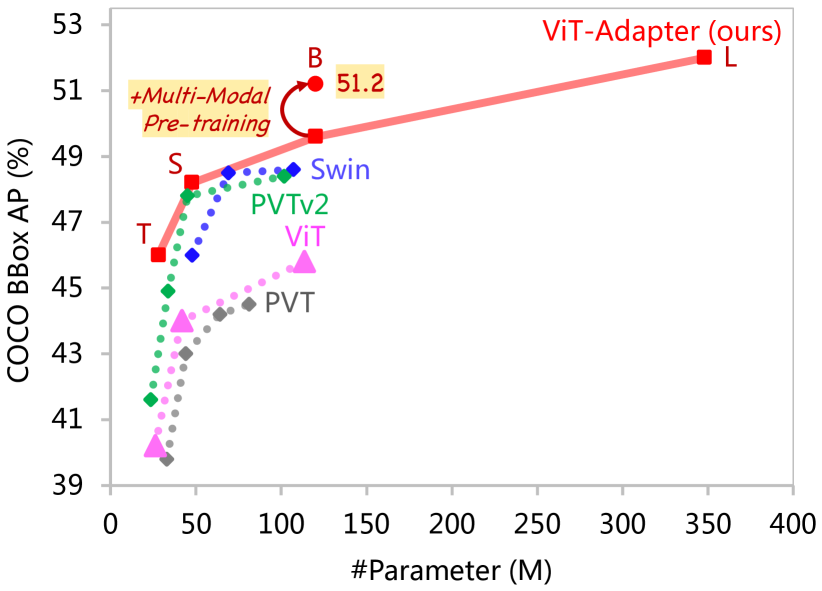
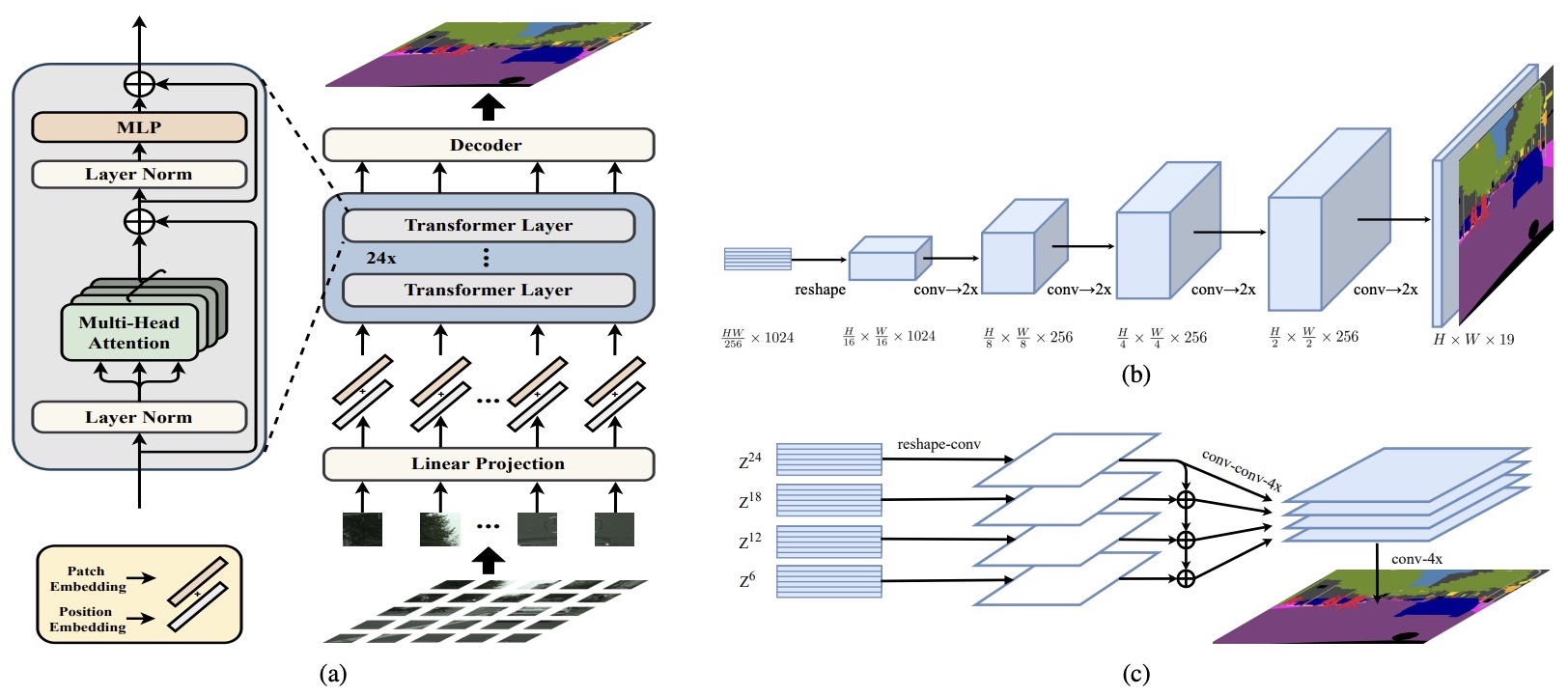
2205.08534] Vision Transformer Adapter for Dense Predictions

Recent Developments and Views on Computer Vision x Transformer, by Akihiro FUJII

Review — ConvNeXt: A ConvNet for the 2020s, by Sik-Ho Tsang

A Broad Study of Pre-training for Domain Generalization and Adaptation

The freeze out distribution, f f ree (x, p), in the Rest Frame of the

Our OOD accuracy results compared with the best reported numbers in
We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on

NeurIPS 2023
Aman's AI Journal • Papers List

Review — ConvNeXt: A ConvNet for the 2020s, by Sik-Ho Tsang