Reinforcement Learning as a fine-tuning paradigm
$ 17.99 · 5 (274) · In stock

Reinforcement Learning should be better seen as a “fine-tuning” paradigm that can add capabilities to general-purpose foundation models, rather than a paradigm that can bootstrap intelligence from scratch.
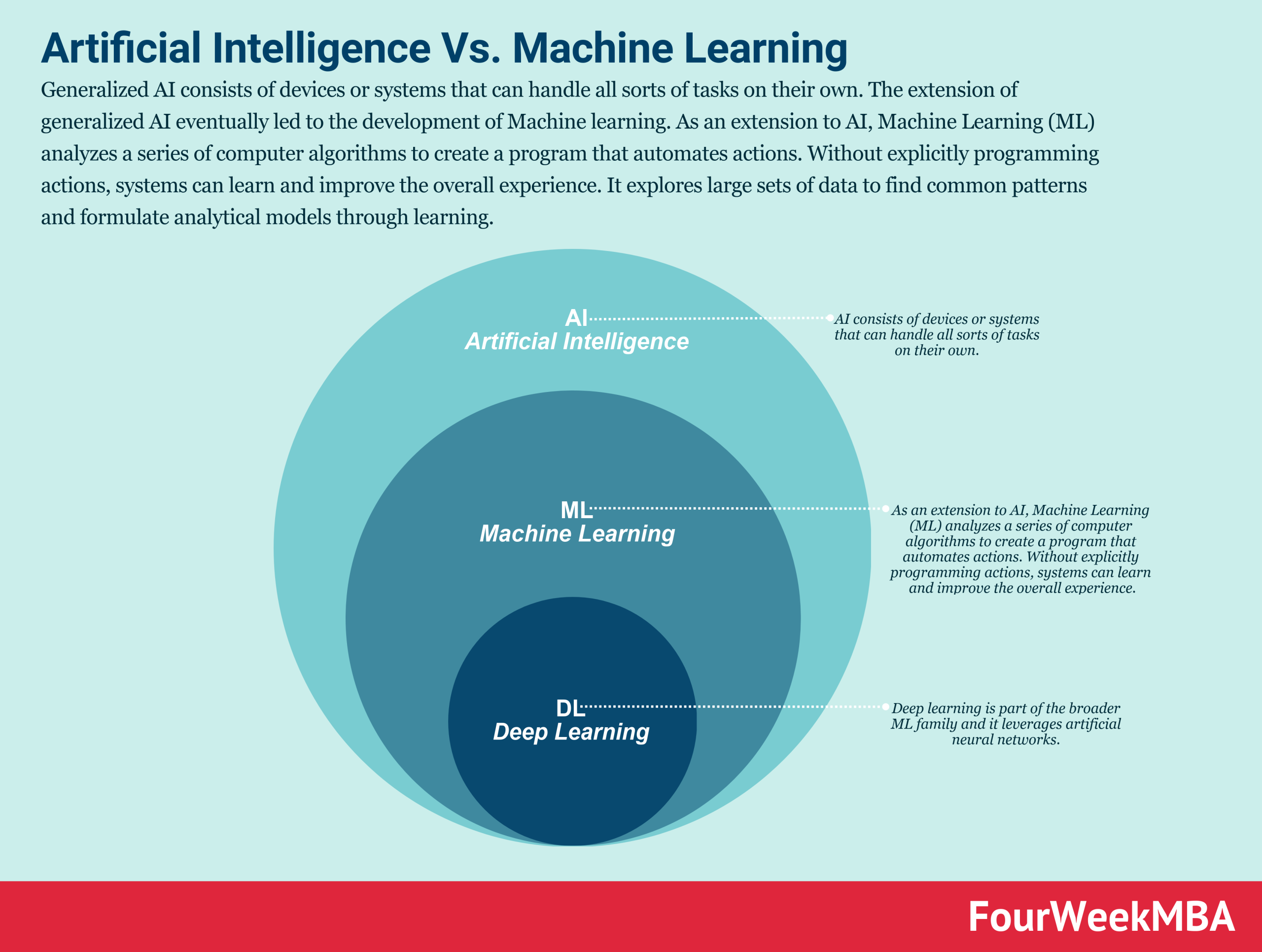
Artificial Intelligence Vs. Machine Learning - FourWeekMBA

5: GPT-3 Gets Better with RL, Hugging Face & Stable-baselines3, Meet Evolution Gym, Offline RL's Tailwinds

5: GPT-3 Gets Better with RL, Hugging Face & Stable-baselines3, Meet Evolution Gym, Offline RL's Tailwinds

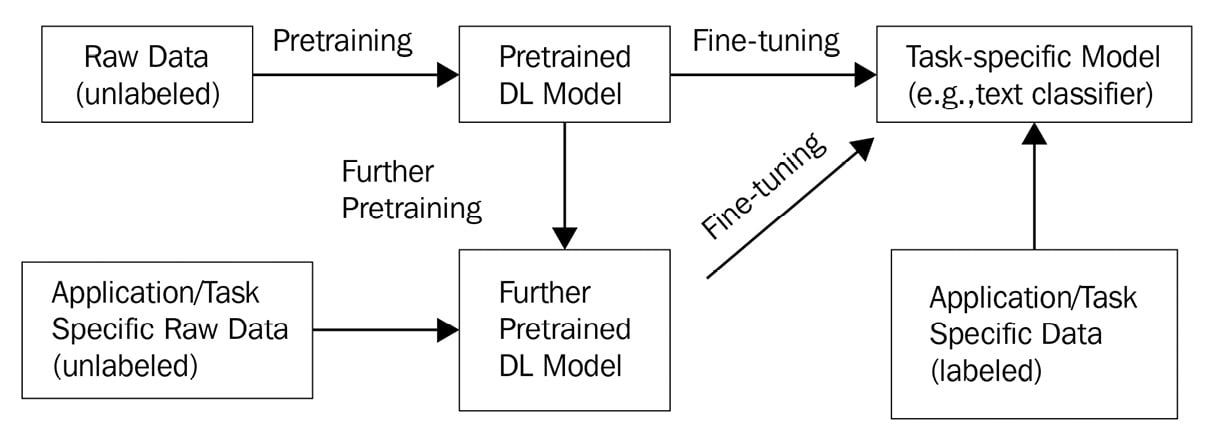
Reinforcement Learning for tuning language models ( how to train
![]()
What is Reinforcement Learning? – Overview of How it Works

Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
Packt+ Advance your knowledge in tech

Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU

RLHF & DPO: Simplifying and Enhancing Fine-Tuning for Language Models
.png)
Non-Generalization and Generalization of Machine learning Models
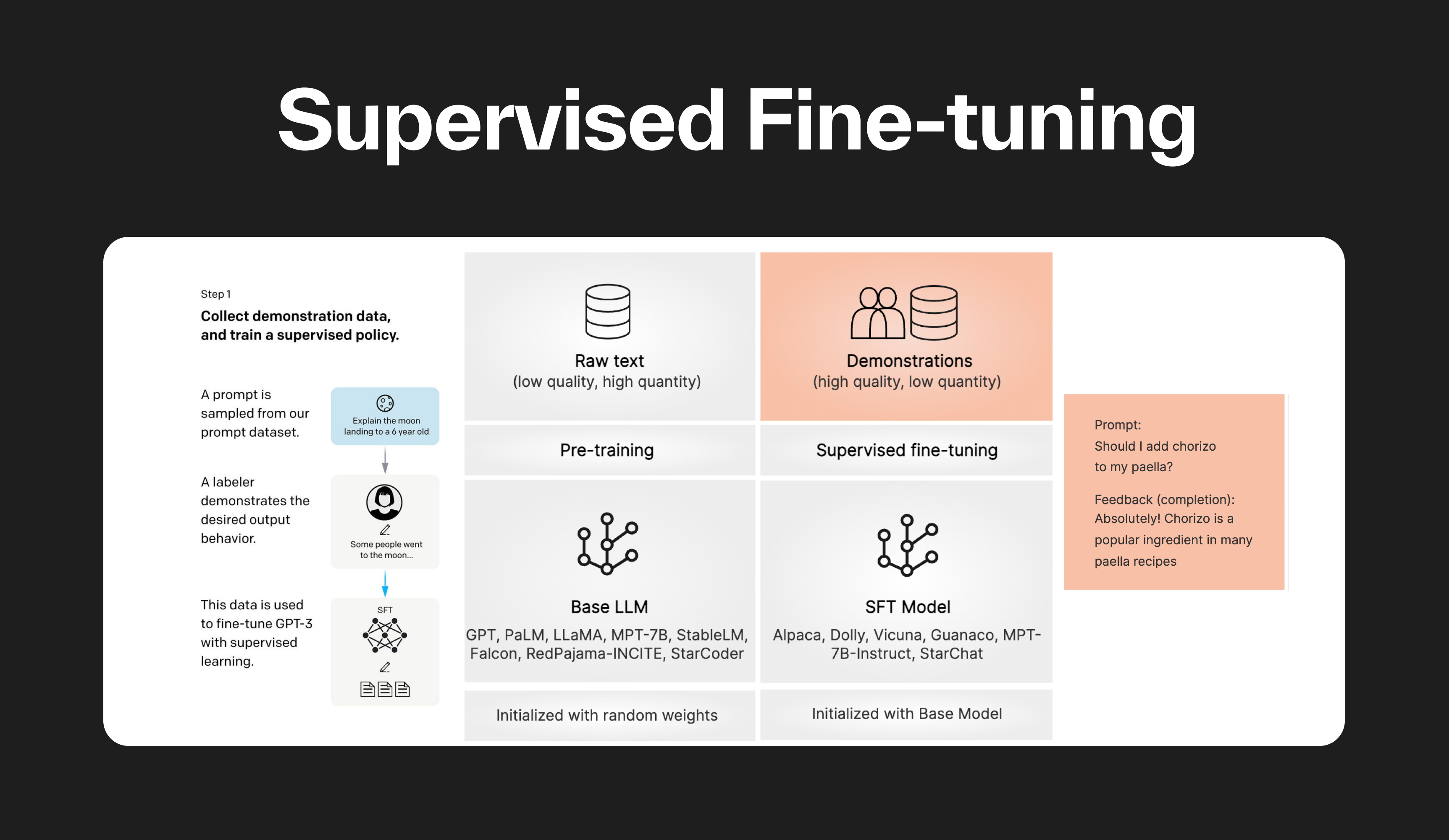
What is supervised fine-tuning? — Klu

Emergent Mind on X: Reflexion revolutionizes LLMs by using verbal

Active Learning in Machine Learning [Guide & Examples]

The uneasy relationship between deep learning and (classical